“深扒术语不装逼,实战真知变牛逼。”
传统评分模型开发大致可以分为以下几个步骤:
- 准备模型数据
- 分箱 - Binning
- 分箱后变量对模型贡献的评价 - WOE、IV
- 建模 - Logistic Regression
- 模型稳定度 - PSI
本篇文章主要讲前两个:模型数据准备和分箱。
什么叫模型数据?评分卡模型需要准备什么样的数据?
数据采集之后,一般以数据库的形式记录下来。做模型的样本数据,需要把每一个贷款人形成一条记录。也就是说每一行就是一个贷款人的所有相关的信息。
我们说的评分卡数据一般是对借款人或者是贷款人,违约风险的一个量化的预测。
再白话一点就是:借钱给一个人之后,有多大的概率会不还钱。
那么模型数据大概会包括哪些方面呢?
比方说央行的征信数据,是所有银行以及持牌金融机构,被强制要求上报的数据。这些数据基本与借贷高度相关。目前央行的征信数据还包括了公共事业的信息,接下来涵盖面会越来越广。所以能够使用央行的征信数据来做预测,是非常好的一件事情。
上篇文章中案例里的数据也属于一个代表的典型。有借款人的基本信息,贷款用途、负债情况,财富收入情况等等信息。每一个方面都会有体现为一个或者多个字段来代表。
那么什么叫字段?或者说变量?
字段或者变量就是有明确含义的,具体信息,采用数字或者文本的形式进行记录。
通常情况下,字段 = 变量 = 列。
比方说,有个字段叫做年龄。那么这个字段/变量/列是指每个用户具体的年龄,存储的方式是数字。由于每个用户的年龄肯定不会是完全一样的,所以就叫做变量。变量就是说可变的量,不管是数字还是文本。
再举个例子,比方说城市,那么城市肯定是以文本的形式进行存储。
变量的类型大体可以粗分为两类。一类是数字,另一类是文本。
大家不要嫌我啰嗦,因为这个基础概念非常重要,接下来讲的是,所有的统计模型不管是我们在讲的这个案例,还是其他的机器学习或者是建模,都会要处理这两种类型的变量。
处理不同类型的变量一定会涉及到一个问题,就是处理完的变量,是一个什么形式?
为什么这么说呢?如果处理完的形式不统一,或者说量纲不统一,模型是没有办法做下去的。
举个例子,一斤米和10本书,不管是数量单位,还是东西本身都是没有办法比较的。那么可以想象到的一个对比方式是什么呢?一斤米多少钱?10本书多少钱?从这个角度讲,折换成钱之后一斤米和10本书就可以在货币的角度进行比较。
再举个例子,100个男生和100个女生,虽然都是100个人,但是他们的风险水平肯定是不一样的。这就需要转换成统一的量纲,把量纲单位不一样的事物能统一能够进行比较。
接下来引出下一个概念就是,
为什么需要分箱?
在传统的建模模型里,首先要在形式上统一数字变量和文本变量。可以想象到的方式就是把数字变量和文本变量都处理成分类变量。
什么是分类变量呢?表现形式就是文本。
比方说城市,城市可以怎么分类呢?比如说一线城市二线城市等等。数字型的变量怎么分类呢?比如说20多岁,那就可以分在20-30岁这个区间段,30多岁可以分在30-40岁这个区间段,那么表现形式也是文本,这就是所谓的分类变量。
再简单点说,分箱对于数字变量就是分段,对于文本变量就是合并。
分箱的合并,或者分段,都是基于统计学的算法来计算的,分段出来的情况,人类并不一定能完全理解为什么,这个时候一定要加入一定的业务输入。
比方说年龄好了,10岁或5岁分段都可以,但有时候会看到,18-22会是一个特殊的分段,因为这段时间,很可能就是大学生念书的时间,所以要有一个业务的解释。
你不能分出来假设说21~27,这个分段可能是根据数据分出来的,但是对于业务人员来说,这是很难理解的。他们只能理解到刚才讲的,5岁或者10岁,还有特殊一点的,23岁。其他的分法可能就无法理解为什么了。
所以在数据表现允许的情况下,尽可能结合业务知识进行分段。
传统的评分模型,首先在变量的处理上,用分段、合并的方式变成了文本。这是形式上的统一,当然会有后续的作用。
也有些算法模型,处理方式是反过来的,也就是把文本处理成数字,比方说XGboost。XGboost是文本变成数字,然后用矩阵的方式进行处理。
不管是哪一种,都会在形式上先统一,要么处理成文本,要么处理成数字。
如何分箱,其实有不同的算法,常见的有决策树(tree)、 卡方(ChiMerge)。具体的算法这里不展开说,大家先有个印象。
OK,处理成文本有什么好处呢?接下来就会引入下一个概念,就是分箱之后,如何去评价变量的有效性。
许多的文章中讲的术语:“离散化”,就是我们刚才讲的这个过程。所以为什么术语难懂,一定要用大白话来讲清楚。
WOE和IV
首先记住这两个单词。
每一个字母你都认识,但是合起来你就不知道它的意思,这就是术语。
这两个是需要计算的衡量指标。对于二分类模型,这两个指标的意义非常重要。
刚才又讲了一个术语,叫做二分类模型。什么叫二分类模型呢?
目标变量y,只有两个值,比方说0或者1。那么在示例里边1代表坏用户,0代表好用户。
这里再稍微啰嗦一下,在建模数据的准备阶段。好和坏用户的定义非常重要。尤其要注意的是,不能是非坏即好,在下一个章节里边会专门讲。
两个指标的公式在网上很多地方都能够搜得到,不展开讲。我们只讲有什么作用。
WOE是看分箱之后变量中不同分组呈现出来的数据指标的单调性。
什么是单调性呢?就是说WOE指标通过不同分箱画出来之后,是否呈一条直线。比如下图: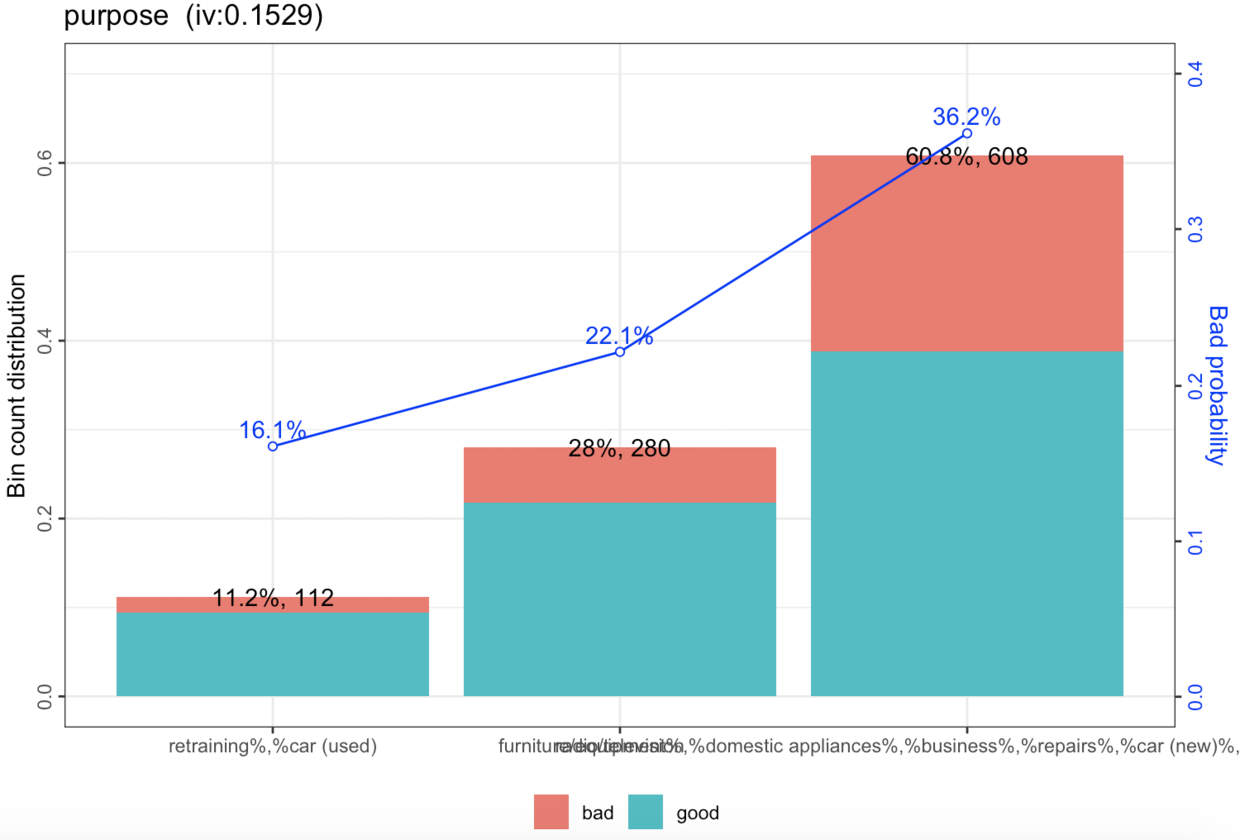
为什么要成一条直线呢?因为理论上传统评分模型其实概念上是在做线性回归。
这条线要尽可能陡峭,不管是前低后高,或者是前高后低,越陡峭越好。如果画出来比较水平的直线,那说明这个变量对于模型的贡献很低,也就是对于好坏用户的区分能力一般。
这么讲还是有点抽象,讲个具体的例子吧。
举个例子,比如说,我们把年龄切成5段,然后发现年龄越大的人,他的违约的概率越小。那么你就可以直接把年龄段和对应的违约化成如下图,它就是一条直线: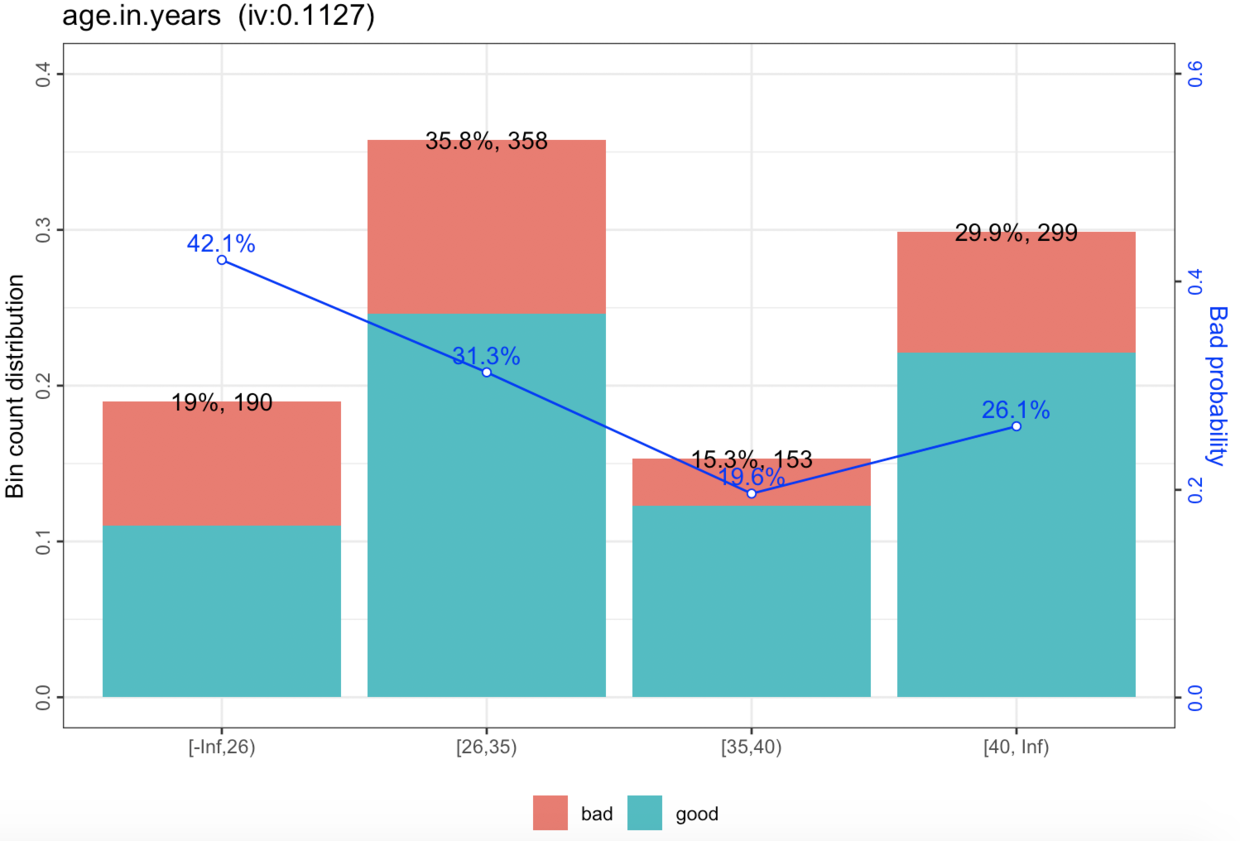
(上图并没有完全是一条直线,姑且这么看吧)
在WOE的计算里边需要引入了一个概念:Odds。这个词的意思代表坏客户的占比除以好客户的占比。某些特殊的软件比如SAS,专门说了叫Good Bad Odds,也就是反过来,好客户的占比除以坏客户的占比。
比如某个年龄段,好人占了80%,坏人占了20%(因为是二分类模型,目标变量只有这两种情况)。所以:
- Odds:20%÷80% = 0.25
- Good Bad Odds:80%÷20% = 4
然后对除出来的比例,进行对数转换,对数转换是以自然对数为底数的。
为什么要以自然对数为底数,为什么要做对数转换?这个在后续的章节里边讲。
目前大家只需要知道,画这个图的目的就是尽量弄成直线,直线越陡说明区分能力越强。
在实际操作里边WOE能完全成直线的,是比较难见到的。通常可以接受的,比如说是一个U型或者是一个倒U型的结构,这种结构,我们可以通过简单的数学变换进行处理,也就是把它掰直,怎么掰直呢?后续章节会讲。
但是一定不能接受的就是类似心电图这样的表现,没有办法掰直了,从实际上讲心电图变量代表趋势不明确,不能放入线性模型。
直线越陡峭说明变量区分能力越强,如何定量的描述变量的强度?就引入了IV值。
什么是IV值?
全称是Information Value,也就是信息价值的意思。
IV值的计算在全网也有不少的介绍。通过一个数学量化的方式来体现变量分箱之后整个变量的强弱程度。具体这个变量有多强有多弱,可以参考以下:
- IV< 0.02 , 没有预测能力
- 0.02 <= IV <0.1, 预测能力弱
- 0.1 <= IV <0.3, 预测能力中
- IV >= 0.3, 预测能力强
IV的数字越大就说明变量的强度越大。
但是物极必反嘛,如果大于0.5,那要考虑这个变量是不是过于强了。
有同学会不理解,强不好吗?
太强的变量,会导致其他变量很难进入模型,因为其他的变量相对太弱了,就会变得不需要了。
还是会有同学不理解说,用最少的变量就能做好模型,不是挺好的吗?
因为模型还是要服务业务,业务需要稳定。如果只有少数的变量,相当于所有鸡蛋都放在少数的篮子里面,当这些少数的信息出现问题的情况下,就没有其他的信息可以做判断了。
再说得简单些,如果入选的变量,都能在0.1~0.3,是比较好的,说明变量也都比较强,变量最好是涵盖不同方面的,这样你的模型就会稳定而且精确度高。
在之前的示例里边,默认的筛选的IV值,设置的是0.02。也就是说变量IV值需要大于0.02,才被选入作为模型的入参变量。
好的,这篇我们稍微做个总结:
- 数据信息体现在变量/字段/列,粗分为数字变量和文本变量。
- 传统模型要对变量进行转换,需要转换成文本分类变量。
- 把数字或者文本变量转换成分类文本变量的过程,叫做分箱。
- 分箱之后可以通过WOE来看图像的单调性,图像越单调,越陡峭,说明变量的区分能力很好。
- 具体区分能力的量化值可以通过IV值的计算体现。
以上是本期的内容,谢谢啦。


